공부/논문
A Study on the Efficacy of model pre-training in Developing Neural Text-to-speech System
내공얌냠
2024. 12. 9. 21:24
ICASSP 2022
https://arxiv.org/abs/2110.03857
Introduction
- In research, the text content of training and test data are often highly similar and in the same text domain. For many real-world applications, TTS systems need to deal with text input with arbitrary content across a wide range of domains.
- specific target speakers 로부터의 데이터를 증가시키는 것 : costly or impractical → “non-target” speakers 의 데이터를 사용하는 것 : easily accessible and available. but uncertain and unstable (데이터의 content, quality 에 따라)
- 3 aspects of consideration
- converge and domain of text content (→ this study mainly focused on this aspect)
- speaker similarity with repsect to the target speaker
- acoustic condition
- Prosody : naturalness, expressiveness 를 결정짓는 중요한 요소. prosody variation 가 두 가지 컴포넌트로 구성되었다고 가정하면,
- text-based variation : text prosody, refers to the general prosodic characteristics tha tare basic and essential to expressing the intended text content. e.g. lexical tone, lexical stress, sentence intonation native speaker 가 생성한 IPA 전사에서 non-native speaker 의 발화 시 native listener 는 이상함 감지 가능
- speaker-based variation : speaker prosody, is concerned primarily with an individual’s speaking style. (In particular, we differentiate it from timbre, which refers mainly to voice (phonation, 발성) characteristics.)
- Speaker-independent TTS model deals with only text information regardless of speaker variation. After being fine-tuned, this model would supposedly retain the text prosody learned during pre-training. So effective pre-training with diverse text content can contribute to the performance of the target speaker TTS system in aspect of handling domain-mismatched text.
Contribution
- Using diverse speech data to pre-train a speaker-independent TTS model can improve the performance of the target speaker TTS on domain-mismatched text.
- Test sets with different degrees of similarities to the text domain of target speaker data are designed.
- Propose a method to improve the data and computational efficiency by reducing the pre-training data for a specific new text domain.
Data
- Pre-training data : LibriSpeech, around 100 hours of speech data from 2484 speakers, based on the LibriVox’s audiobooks, which have a comprehensive coverage of topics. For the investigation on data reduction, 40,000 text-audio pairs (around 1/8) are used.
- Target speaker data : LJSpeech, contains 13,100 (about 24 hours) audio clips of high-quality English speech produced by a female speaker reading passages from 7 non-fiction books. Experiment fine-tuned with the whole LJSpeech corpus or its subsets of smaller size
Experiment
Effect of pre-training on target speaker TTS performance
- Two systems
- TTS w/o pre-training is trained only on target speaker data. i.e., without pre-training with other data
- TTS w/ pre-training is built by applying target speaker data (LJSpeech) to fine-tune a speaker-independent model pre-trained with LibriSpeech
- Three test sets, domain-mismatched test sets
- collect around 50,000 sentences from various sources. test sets each has 60 sentences.
- A phoneme-based subword bigram language model is trained on text domain of target data. the phoneme-level subwords for each word are obtained by applying Byte Pair Encoding (BPE) to the phoneme sequence of the word. vocab size is 200. this language model applied to calculate the perplexity scores for all 50,000 sentences in the general text set. A sentence similar to the text domain → low perplexity
- T-SIM : the texts with the top 60 lowest perplexity scores, same or similar domain
- T-RAN : the 60 text are randomly from the general text set
- T-DIFF : the texts with the top 60 highest perplexity scores, low degree of similarity to the text domain
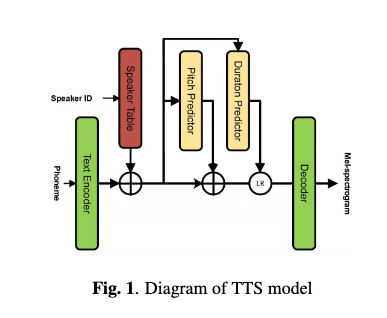
- TTS Model
- Trainable speaker table and a speaker-independent TTS model
- speaker table models the voice characteristics for individual speakers
- speaker-independent model follows the NAR TTs system FastSpeech 2
- the model predicts pitch at phoneme level, this give better TTS performance than frame-level prediction in FastSpeech 2
- Text encoder : phoneme sequence —convert—> text embeddings , combined with speaker embeddings to predict the pitch and duration using the respective predictor modules.
- Length regulator (LR) : all phoneme-level features —upsample—> frame-level features
- Decoder : frame-level features transformed into mel-spectrogram
- Melgan vocoder : generate speech waveform from the mel-spectrogram
Pre-training data reduction for a new text domain
- aim to improve the target speaker TTS performance on a specific new text domain
- assume that the speaker-independent model pre-trained on the data similar to the new text domain can effectively transfer the text-based prosody to the target speaker TTS system.
- Two methods are developed to select data with high text similarity to the new text domain from the LibriSpeech corpus
- Perplexity-base method
- on phoneme-based subword bigram language model, text corpus with low perplexities is assumed to have a high degree of similarity to the new text domain.
- the corresponding pairs data will be selected as pre-training data
- BERT-based method :
- BERT learns general-purpose text representation, is trained on a large amount of open-domain text data.
- The sentence-level vector is obtained by performing average pooling on token representations from the last encoder layer of BERT over a sentence.
- The new text domain can then be represented by the centroid of the sentence-level vectors belonging to the new text domain
- the degree of similarity between each text and the new text domain is measured by the L2 distance between the sentence-level vector of that text and the centroid vector of the new text domain.
- the data with high text similarities to the new text domain will be selected as pre-training data.
- Perplexity-base method
Results and Analysis
Subjective evaluations on domain-mismatched text
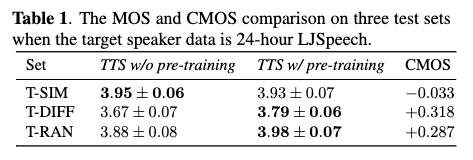
- Table 1
- TTS w/o pre-training : highest MOS score on T-SIM, lowest on T-DIFF → TTS w/o pre-training performance will drop as the text is different from the domain of target data.
- T-DIFF, T-RAN : TTS w/ pre-training > TTS w/o pre-training → the pre-trained speaker-independent model improves the performance of target speaker TTS on the domain-mismatched text (pre-train 모델이 더 성능 좋음)
- C/MOS gap between two systems, T-DIFF > T-RAN → the improvement is more significant as the test text is more different from the text domain of the target speaker data. (두 시스템은 텍스트 도메인이 다를수록 더 차이남)
- T-SIM : TTS w/ pre-training shows no gain, in contrast to TTS w/o pre-training → the text-based prosody learned from the pre-trained speaker independent model does not benefit the TTS w/ pre-training on T-SIM
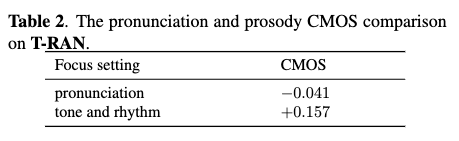
- Table 2
- compared with the baseline TTS w/o pre-training, TTS w/ pre-training mainly improves prosodic variation of speech instead of pronunciation.
- TTS w/ pre-training achieves improvement on the domain-mismatched text is that the text-based prosody learnt from pre-training data can be transferred to the target speaker TTS system
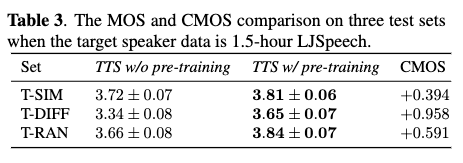
- Table 3
- 1.5 hours subset for finetuning
- perform TTS w/ pre-training > TTS w/o pre-training
- 1.5 hours is sufficient for TTs system to produce intelligible speech, but TTS w/o pre-training still sounds unstable and jittery due to model overfitting
- improvement is the most notable on T-DIFF, the least marked on T-SIM (same as that in Table1)
- T-SIM : TTS w/ pre-training > TTS w/o pre-training (different result in Table 1) → TTS w/ pre-training has more stable voice, it means the TTS w/ pre-training mitigates the overfitting problem when the target speaker data is limited
TTS performance evaluation on pre-training data reduction for a new text domain
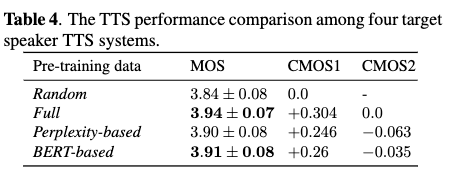
- Table 4
- 60 sentences are randomly sampled from the new text domain. Four target speaker TTS systems. All four target speaker TTS systems are fine-tuned from pre-trained speaker-independent TTS models.
- only difference is the pre-training data
- Random : 40,000 pairs data randomly sampled from the LibriSpeech, which is used as the baseline system
- Full : LibriSpeech
- Perplexity-based : 40,000 pairs data sampled from LibriSpeech with the perplexity-based method
- BERT-based : 40,000 pairs data selected from LibriSpeech using the BERT-based method
- CMOS1 : TTS system with proposed method can significantly improve TTS performance on the new text domain compared with the system with the random pre-training data(baseline).
- CMOS2 : both proposed method based pre-training data are comparable to the topline system
728x90
반응형