VALL-E X
관심 있는 부분만 요약했습니다..
https://arxiv.org/pdf/2303.03926
conditional language modeling task with neural codec codes
AR language model 를 사용한 paired phoneme sequences 로부터 첫번째 Encodec quantizer 로 audio codec 을 만들고, 그 코덱들을 나머지 quantizer 로 병렬로 NAR model 을 이용해서 코드를 생성한다
multilingual autoregressive codec LM, multilingual non-autoregressive codec LM 이 acoustic tokens 를 서로 다르게 세부적으로 생성
acoustic quantizer, vall-e 에서처럼 Encodec, encoder-decoder model with L(8) quantization layer, 각 레이어는 75hz 에서 1024의 quantized code 생성
multilingual AR codec LM
autoregressively generates acoustic tokens,
only used to predict the acoustic tokens from the first quantizer layer of EnCodec model
from semantic tokens (phoneme sequence) -> acoustic tokens
decoder theta mar is optimized by maximizing the log-likelihood
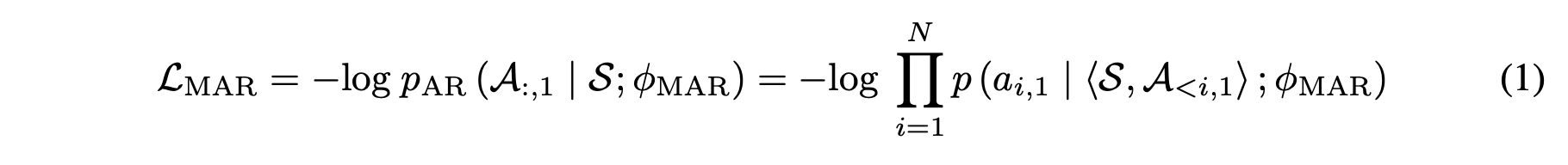
S : the transcribed phoneme sequence
A : first-layer acoustic tokens extracted from speech X
decoder theta mar : modeling the concatenated sequence <s, a>, is trained to predict A autoregressively.
<> : sequence concatenation operation
p(.) : softmax function
multilingual NAR codec LM
non-autoregressive transformer language model aiming at iteratively generating the rest layers of acoustic tokens from the first layer
S : the phoneme sequence of the current sentence
A~ : the acoustic token sequence of the another sentence with same speaker, from the previous sentence in the dataset where the adjusted sentences are usually segmented from the same paragraph. it is expected to have the same characteristics of voice as the current sentence and is used as an additional reference for cloning the target voice
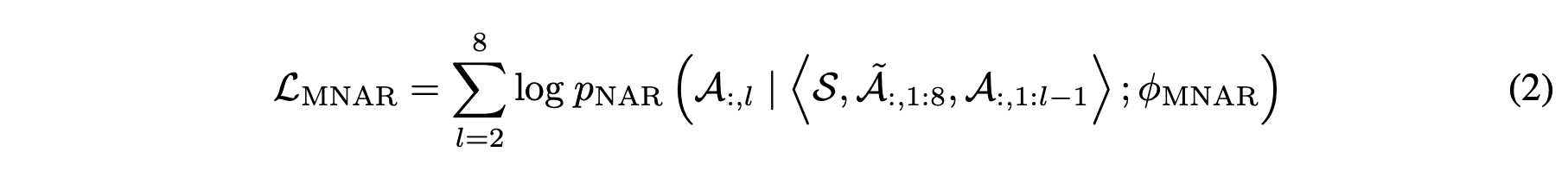
each layer l
A : the embeddings of l-1 layers' acoustic tokens, summed up layerwise as input
the learning objective for the l-layer acoustic tokens A can be calculated as (2)
multilingual training
take advantage of bilingual speech-transcription corpus, pairs of (S^s, A^s), (S^t, A^t)
Language ID Module:
to guide the speech generation for specific languages
maybe confused to select suitable acoustic tokens for the specific language since it is trained with multilingual data
different characteristics for example tones, which increases the difficulty of adjusting the speaking style across languages.
adding language info is surprisingly effective in guiding the right speaking style and relieving the L2 accent problem
we embed language ids into dense vectors and add them to the embeddings of acoustic tokens
without LID or wihout wrong LID, the translation quality decrease, while the speaker similarity between hypothesis and source speech increase.
the target LID reduces the transfer of information, which means the model without LID or with source LID will better maintain the sound of the original speaker.
foreign accent control
L2 (second-language, or foreign) accent problem, the synthesized speech sounds like the accents of a foreigner, has arisen in cross-lingual TTS systems.
adding LID can boost speech quality
by using correct LID embedding, the model trans is able to alleviate the foreign accent problem
Code-Switch Speech Synthesis
aims to produce a fluent and consistent voice for code-switch text
without special optimization for code-switch setting, the model provides a promising solution to code-switch speech synthesis
due to its strong in-context learning ability, model can synthesize fluent code-switch speech with a consistent voice.
phonemization & quantization
unified phoneme set english and chinese : https://github.com/speechio/BigCiDian
EnCodec, which employs residual vector quantization to iteratively quantize speech to a codebook according to the residual after quantization
Training details
When optimizing φMNAR, instead of accumulating all layer’s loss in Eqn. (2), we randomly select one layer at each optimization step for efficiency. < 신기하당,,,
Inference
source speech X^s 가 주어지면,
semantic encoder -> source phonemese S^s 생성
semantic decoder -> target phonemes S^t 생성
Encodec -> source acoustic token A^s
concate S^s, S^t, A^s
-> VALL-E X
-> acoustic token sequence for target speech
-> Encode decoder
-> final target speech