
읽은 이유:
Mediapipe Face Mesh 공부
논문 내용:
Abstract
하나의 카메라 인풋으로 AR 어플리케이션을 위한 3D mesh 표현을 하기 위해서 end-to-end neural network-based model 을 구현
얼굴 기반의 AR 효과들을 위해 잘짜여진 468개의 정점들 vertices 이 존재.
1. Introduction
facial geometry 를 예측하는 것의 문제점:
aligning a facial mesh template == face alignment == face registration
보통은 각기다른 의미와 얼굴 컨투어에 의미있는 (일반적으로 68개) 의 landmarks 혹은 keypoint 로 이루어진다.
다른 접근으로 3DMM(3D morphable model) 이 있는데, 이것은 많은 포인트들을 가지고 있지만 자세한 예를 들어보자면 눈 한쪽이 감겼을 때 제대로 얼굴을 확실히 표현하지 못하는 것처럼 보인다.
각 정점을 독립적인 landmark로써 다뤘고, mesh topology 는 고정된 사각형 fixed quad 안에서 468 points로 구성된다.
아래와 같은 Figure2 (a)와 같이 나타나고, 이것을 응용하면 Figure2 (b)와 같이 만들 수 있다.

input : RGB camera의 frame (depth-sensor 카메라는 필요없어요!)
output: Figure 1 과 같은 형태가 나온다.

target: real-time mobile GPU inference(<- full model), mobile 에서 CPU inference 를 위한 가벼운 버전(<- lightest model)
2. Image processing pipeline
1. 카메라로부터 받은 input 전체 프레임을 lightweight face detector를 이용하여
- face bounding rectangles
- several landmarks(eye centers, ear tragions, and nose tip)
를 생성하고, 이 landmarks 은 facial rectangle 를 해당 rectangle의 eye centers의 수평에 맞게 맞추도록 회전시키는데 사용됩니다.
2. 이전 프로세스에서 rectangle은 원본 이미지에서 crop 되고 resize되어 256 x 256 -> 128 x 128
이 모델은 3D landmark coordinates의 vector를 생성합니다. (이 vector는 나중에 원본 이미지 coordinate system으로 맵핑됩니다.)
face flag:
- a distinct scalar network output
- probability 를 생성함(제공된 crop에 어느정도 정렬된 얼굴인지)
x-coordinates, y-coordinates : 2D 평면의 point locations
z-coordinates :
- depth
- re-scaled 되서 x-coordinates 의 span과 z-coordinates의 span 사이에서 고정된 aspect 비율이 유지됩니다.
- 예를 들어 얼굴은 그 반으로 사이즈가 줄어들고 depth range 도 같은 곱으로 줄여집니다.
face tracking mode:
- 잘된 얼굴 crop의 경우 다시 face detector 를 사용하는 것은 낭비일 수 있어서, 이럴 경우 첫번째 프레임에서 사용하고 (적절한 threshold의 아래로 떨어지는 face flag 에 의해 probability가 예측된 이후) 이런 상황의 드문 이벤트가 발생될 때 face detector를 사용합니다.
- 이런 설정 안에서, 두번째 네트워크는 적절하게 중간으로 맞춰지고 정렬된 얼굴들을 input으로 받게 됩니다.
3. Dataset, annotation, and training
training
- 빛이 비춰지는 조건이 변화하는 상황의 센서의 넓고 다양하게 찍힌 30K개 정도 되는 in-the-wild한 모바일 카메라 사진의 dataset
- training 중에, 기본적인 cropping과 image processing primitives, 그리고 조금 특별한 것들을 dataset을 축적시킵니다. 조금 특별한 것들은 카메라 센서 노이즈를 모델링 하는 것, image intensity histogram을 위한 랜덤화된 비선형적 non-linear parametric transformation 을 적용하는 것입니다.
468개의 3D mesh points를 위한 기반 사실은
- labor-intensive
- highly ambiguous task
포인트 하나하나를 알려주는 대신 우리는 아래의 반복되는 프로시저를 따른다.
- 초기모델을 아래 두 개의 소스를 사용하여 학습시킨다
- 실제 세계 사진들의 얼굴 사각형들 위에 3DMM 을 합성 랜더링 (기반 정의된 정점 좌표는 468 메쉬 포인트와 3DMM 정점들의 일부 사이에서 주고받은 미리 정의된 것들로부터 즉시 가능하게 합니다.)
- 메쉬 정점들의 작은 부분에 따라 2D landmarks를 의미 있는 컨투어들의 집합에서 포함시키면서 실제 "in-the-wild"한 dataset 의 위에 표시합니다.(figure 3) landmarks는 분리된 output으로써 network branch 전용의 마지막에 예측됩니다.
이 첫번째 모델이 학습된 이후, 데이터셋의 이미지 30% 정도가 이어지는 단계에서 개선되기 위한 적절한 예측을 가지고 있습니다.
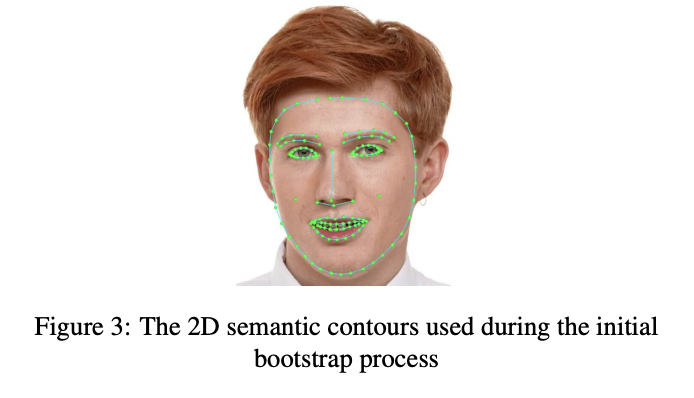
2. 최신 모델을 적용하면서 반복적으로 x-, y-coordinates bootstrapped를 다듬습니다. 이런 정제를 위한 이러한 적절함을 필터링하면서. fast annotation refinement는 모든 범위의 포인트를 한번에 이동하도록 하는 적절한 radius와 함께 "brush" 명령에 의해 가능하게 됩니다. 이런 움직임은 마우스 커서 아래의 피봇 정점으로부터 메쉬 가장자리를 따른 거리에 따라 기하급수적으로 줄어듭니다. 이것은 annotators 가 local refinements 이전에 실제 영역의 전치를 큰 "strokes" 와 할 수 있게 허락합니다. (메쉬 표면의 부드러움을 제공하기 위해서) 우리는 z-coordinates가 원래대로 남는 다는 것을 알고 있습니다. 그들을 위해 위에 라인으로 표시된 의미있는 3D 랜더링이 되는 것이 supervision의 유일한 소스입니다. depth prediction이 정확하지 않음에도 불구하고 우리의 실험에서는 충분히 타당하다고 결과를 냈습니다.
4. Model architecture
메쉬 예측 모델을 위해 우리는 커스텀 하였지만 꽤 정직한 residual neural network 구조를 사용하였습니다. 우리는 네트워크의 좀 더 앞의 레이어들에서 더 공격적인 subsampling을 사용하였고, 대부분의 계산을 shallow part 에서 하였습니다.
그래서, neurous receptive fields는 일찍 연관된 input image의 큰 영역을 덮기 시작하였습니다. receptive field가 이미지 영역에 도달하였을 때, 관련된 위치는 절대적으로 모델이 의지하도록 만들었습니다. 결과적으로, 깊은 레이어들을 위한 neurons 은 예를 들어 입과 관련된 features 들과 눈과 관련된 features 들을 구분할 가능성이 높습니다.
이 모델은 이미지 영역을 조금 가리거나 가로지르더라도 얼굴을 완성할 수 있게 합니다. 이것은 결과를 이끌어냅니다. 모델에 의해 만들어진 높은 레벨과 낮은 차원의 메쉬 표현의 네트워크의 마지막 일부 레이어들에서 오직 좌표로 변환된다는 것을 나타냅니다.
5. Filtering for temporal consistency in video
우리의 모델은 하나의 프레임 레벨에서 운영되기 때문에 중요한 정보는 프레임 사이에서 전달되는 회전된 얼굴 bounding rectangle 이다.(그리고 그것이 face detector로 다시 감지되던지 아니던지) 왜냐하면 얼굴의 픽셀 레벨 이미지 표현이 이어지는 비디오 프레임을 지나는 불일치 때문이다. 이것은 사람이 알아볼 수 있는 변동, 임시적은 jitter, 각각의 landmarks의 궤도에서 이어진다.
각 예상된 landmark 좌표를 위해 독립적으로 적용된 한차원 임시적 필터를 적용함으로써 이 이슈를 해결하고자 제시합니다. 특히 1 Euro filter 란 인간과 컴퓨터의 상호작용하는 방법에 영감을 받아 그립니다. 1 Euro와 연관된 필터들의 의 주된 전제는 noise reduction과 phase lag elimination 의 trade-off 입니다.
- noise reduction - 파라미터가 거의 변하지 않을 경우 사람이 선호하는 방법 (i.e. stabilization)
- phase lag elimination - 변하는 정도가 높을 경우 선호하는 방법 (i.e. avoiding the lag)
우리의 필터는 속도 측정을 위한 몇몇 timestamped samples의 고정된 rolling window을 유지합니다. 이것들은 비디오 스트림에서 얼굴 크기 조절을 위해 얼굴 사이즈를 적합하게 하기 위함으로써 조정됩니다. 이 필터를 사용하는 것은 jitter 없이 human-appealing prediction sequences 를 사용하는 것을 유도합니다.
6. Results
MAD(mean absolute distance) : predictions 과 ground truth vertex locations 사이에서 사용
IOD(interocular distance) : normalized, 눈 중앙 사이의 거리를 정의함으로써
이런 normalization 은 얼굴의 크기에서 factoring을 방지하는 것을 목적으로 합니다. z-coordinates는 오로지 의미있는 supervision으로부터 포함되기에, 우리는 오직 2D 에러만 보고하였습니다만, 3D 눈 사이 거리는 yaw 머리 회전 가능성을 설명합니다.
References
https://arxiv.org/abs/1907.06724
Real-time Facial Surface Geometry from Monocular Video on Mobile GPUs
We present an end-to-end neural network-based model for inferring an approximate 3D mesh representation of a human face from single camera input for AR applications. The relatively dense mesh model of 468 vertices is well-suited for face-based AR effects.
arxiv.org
'공부 > 논문' 카테고리의 다른 글
| VITS (0) | 2023.01.06 |
|---|---|
| RCNN : Rich feature hierarchies for accurate object detection and semantic segmentation tech report (v5) (0) | 2022.12.24 |
| ResNet: Deep Residual Learning for Image Recognition 리뷰(작성중) (0) | 2022.12.24 |
| A Survey on Modern Recommendation System based on Big Data (0) | 2022.11.26 |
| BlazeFace (0) | 2022.03.30 |