
Interspeech 2022
https://arxiv.org/abs/2110.05798
Contribution
- present transfer learning methods and guidelines for finetuning single-speaker TTS models for a new voice
- evaluate and provide a detailed analysis with varying amount of data
- demonstrate that transfer learning can substantially reduce the training time and amount of data needed for synthesizing a new voice
- open-source framework, provide a demo
Background and Related Work
- decompose the waveform synthesis pipeline into two steps:
- synthesizing mel spectrograms from language
- vocoding the synthesized spectrogram to audible waveforms
- multi-speaker 는 speaker embedding 으로 컨디션을 추가해서 spectrogram synthesis
- To synthesize the voice of a target speaker, past works have investigated techniques like voice conversion and voice cloning
- voice conversion
- modify an utterance from a source speaker to make it sound like a target speaker
- goal is dynamic frequency warping that aligns the spectra of different speakers
- recently, spectral conversion is encoder-decoder neural networks are typically trained on speech pairs of target and source speakers
- voice cloning
- to synthesize speech for a new speaker (with limited speech data) for any unseen text
- recent works on voice cloning have leveraged transfer learning
- multi-speaker tts model conditioned on a speaker encoder, this speaker encoder is trained independently for the task of speaker verification on a large speaker-diverse dataset. then plugged into the spectrogram synthesizer as a frozen or trainable component.
- the spectrogram-synthesizer can be conditioned directly on the speech samples of the new speaker to perform zero-shot voice cloning, also can be finetuned on the text and speech pairs of the new speaker
- limitation of above techniques
- require a large speaker-diverse dataset during training
- such large-scale multi-speaker datasets are usually noisy and that resuls unsuitable for user-facing applications
- voice conversion
Methodology
- Spectrogram synthesizer
- Use FastPitch and add a learnable alignment module that does not require ground-truth durations (→ not require gt durations)
- FastPitch
- composed of two feed former (FFTr) stacks
- input tokens of phonemes : $x = (x_1, \cdot, x_n)$
- first FFTr outputs a hidden representation $h = FFTr(x)$, used to predict the duration and average pitch of every token
- $\hat{d} = DurationPredictor(h), \space\space\space \hat{p} = PitchPredictor(h)$
- pitch is projected to match the dimensionality of the $h \in R^{n\times d}$ and added to $h$. $g = h + PitchEmbedding(p)$
- the resulting sum $g$ is direcetely upsampled and passed to the second FFTr, produces the output mel-spectrogram sequence $\hat{y} = FFTr([g_1, ..., g_1, ...g_n, ..., g_n]).$
- duration prediction module : use learnable alignment-module and loss ($L_{align}$)
- pitch-prediction module : use ground truth $p$, derived using PYIN, averaged over the input tokens using $\hat{d}$
- mean-squared error between the predicted and ground-truth modalities and the forward-sum alignment loss $L_{align}$ : $L = ||\hat{y}-y||^2_2 + \alpha||\hat{p}-p||^2_2 + \beta||\hat{d}-d||^2_2 + \gamma L_{align}$
- during training : end-to-end on text and speech pairs, $y, p$ are computed in the data-loading pipeline
- during inference : use the predicted $\hat{p}, \hat{d}$ to synthesize speech directly from text
- composed of two feed former (FFTr) stacks
- Vocoder
- HiFi-GAN 구조 설명, unseen speaker 에 대해서 mel-spectrogram inversion 가능하다고 저자 논문이 리포트하였으나 오디오 품질을 위해서는 finetune 했음
- transposed convolution 으로 mel-spectrograms 를 오디오로 upsample
- two discriminator networks
- multi-period discriminator consists of small sub-discriminators. obtain only specific periodic parts of raw waveform.
- multi-scale discirminator consist of small sub-discriminators to judge audios in different scales and learn to capture consecutive patterns and long-term dependencies of the waveform.
- Finetuning Methods
- Direct Finetuning
- finetune all the parameters of the pre-trained TTS models directly on the data of the new speaker
- spectrogram-synthesis model ← text and speech pairs of the new speaker
- vocoder ← only require the speech examples of the speaker
- use mini-batch gradient descent with Adam optimizer using a fixed learning rate
- Mixed Finetuning
- Direct findtuning can result in overfitting or catastrophic forgetting when the amount of traning data of the new speaker is very limited → mix the original speaker’s data with the new speaker’s data during finetuning
- assume that we have enough training samples of the original speaker while the number of samples of the new speaker is limited
- create a data-loading pipeline that samples equal number of examples from the original and new speaker in each mini-batch
- FastPitch 는 speaker embedding layer 가 없어서 만들어줌 (발화자 두 명이니까) during training, lookup the speaker embedding from the speaker id of each training sample, and add it to the text embedding at each time-step before feeding the input to the first FFTr of the FastPitch: $h = FFTr(x + Repeat(speakerEmb))$
- FastPitch 모델 파라미터 ← from pre-trained model, but speaker embedding layer ← randomly initialized and trained along with the other parameters of the model
- vocoder 는 spectrogram representation 이 speaker-specific attributes 를 포함하고 있기 때문에 speaker conditioning 따로 필요 없고, 그냥 두 발화자에 대해서 finetune
- vocoder also use mini-batches with balanced data from the two speaker during finetuning
- Direct Finetuning
Experiments
- Dataset
- Hi-Fi TTS dataset, 292 hours of speech from 10 speakers with at least 17 hours per speaker sampled at 44.1 kHz
- keep aside 50 text and speech pairs from each speaker as validation samples
- train a single-speaker TTS model on female speaker and finetuning experiments on speaker each male and female
- 4 training subsets for each finetuning speaker : 1 min, 5 min, 30 min, 60 min
- for mixed finetuning, mix the new speaker’s data with 5000 samples (~ 5 hours) from pretrain speaker
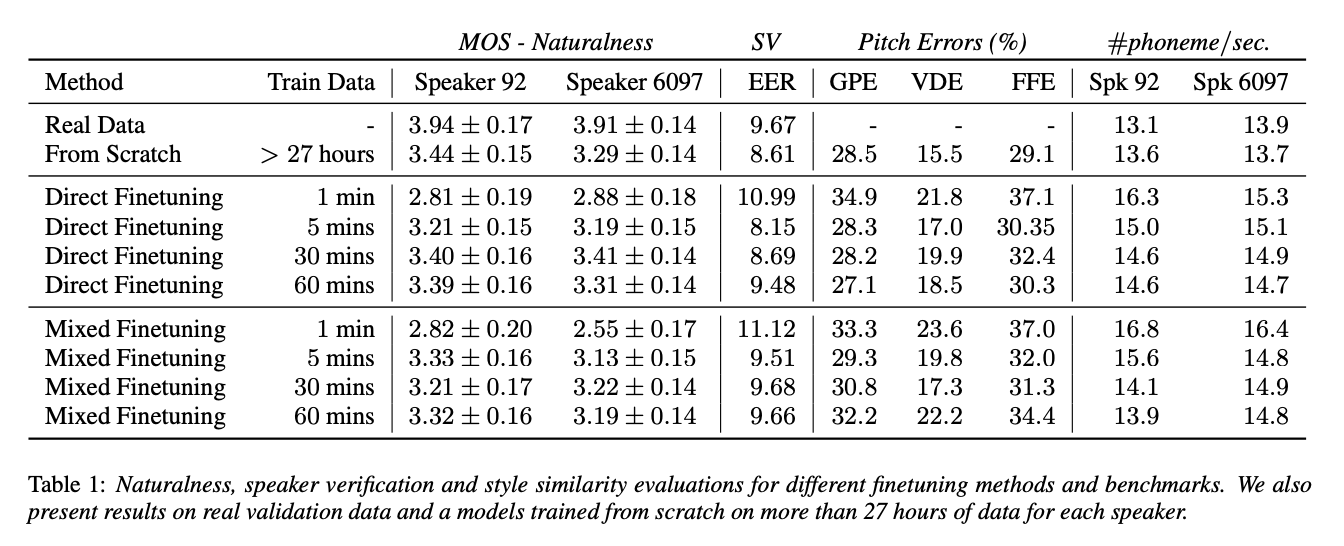
- Metrics
- naturalness
- MOS
- mixed finetuning > direct finetuning
- voice similarity to the target speaker
- visualize the speaker embeddings of real and synth data by reducing the 256 dim utterance embeddings to 2 dimensions using t-SNE (figure 1)
- EER (Equal Error Rate) on synthetic data
- create positive and negative pairs
- close to the on real data observation from the t-SNE plots
- closely mimic the timbre of the target speaker
- speaking style similarity to the target speaker
- error metrics for the pitch (fundamental frequency) contours
- GPE (Gross Pitch Error)
- VDE (Voicing Decision Error)
- F0 Frame Error
- increasing the amount of training data reduces the difference between the speaking rate(phonemes per seconds from samples from text without using forced alignment) of actual data and synthetic speech
- for both speakers, the speaking rate of synthetic speech is much faster than that of the actual data when we use ≤ 5 minutes of dataspeaking style similarity to the target speaker (Table 1)
- naturalness

all image are from reference paper : https://arxiv.org/abs/2110.05798
728x90
반응형