
https://arxiv.org/abs/1609.03499
WaveNet: A Generative Model for Raw Audio
This paper introduces WaveNet, a deep neural network for generating raw audio waveforms. The model is fully probabilistic and autoregressive, with the predictive distribution for each audio sample conditioned on all previous ones; nonetheless we show that
arxiv.org
v1 2016, v2 2016
Introduction
Joint probabilities 를 pixel/word 에 neural architecture 를 사용해서 모델링하는 것은 SOTA generation 을 보여주고 있고, 몇 처 ㄴ개의 랜덤 변수에 대한 분포를 모델링하는 것도 가능해서 (PixelRNN 같이) 이런 접근 방법이 wideband raw audio waveforms 를 생성 시에도 성공적일지,,
Contributions
(정성적으로) 자연스러운 raw speech signals 생성
매우 큰 receptive fields 를 가지는 dilated causal convolutions 를 기반으로 한 새로운 구조 제안
single model 에 speaker identity 를 condition 으로 주면, 다른 목소리를 생성한다
같은 구조로 다른 audio modalities (music, …) 에도 좋은 결과를 보여줌
Architecture
전체 구조
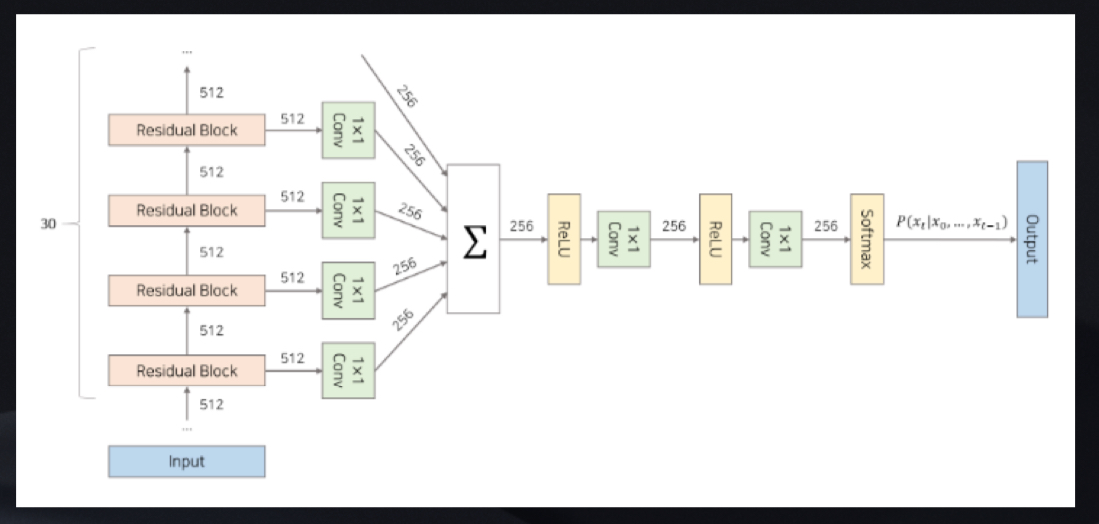
waveform x 의 joint probability
(조건부 확률의 곱으로 인수분해)
조건부 확률은 convolution layers stack 으로 모델링됨
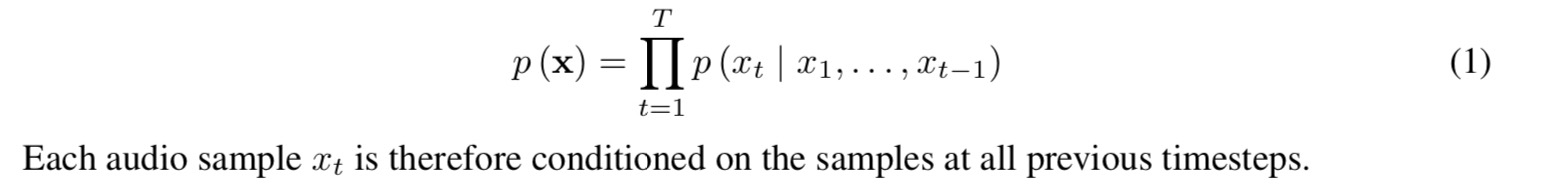
model output 은 categorical distribution (softmax layer) 로 나오고, 파라미터에 대하여 데이터의 log-likelihood 를 최대화하도록 최적화됨
(log-likelihood 는 추적가능하기에 하이퍼파라미터를 튜닝할 수 있고 오버피팅/언더피팅인지 측정 가능)
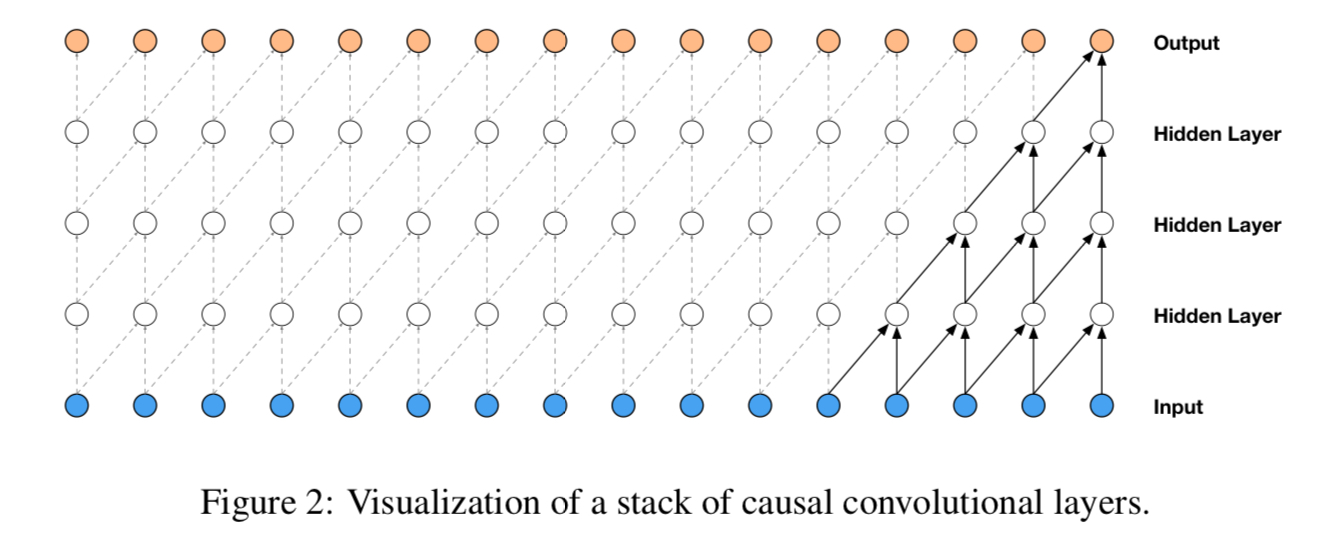
Causal convolution
시간 순서를 고려하여 필터를 적용하는 변형 convolution layer
데이터의 순서를 침범하지 않음
(이미지에서는 masked convolution 과 동일, 1D 데이터인 오디오에서는 output 을 shifting 하여 구현)
학습 시, 모든 timestep 의 조건부 확률은 parallel (모든 timestep 의 gt 를 알고 있으니까) 하지만 생성 시, sequential 각 샘플이 예측되면 다음 샘플을 예측하기 위해 네트워크로 들어감
recurrent connection 을 가지지 않기에 매우 긴 시퀀스에 대해 RNN 보다 학습할 때 빠르지만, receptive field 를 키우기 위해서 많은 레이어나 큰 필터가 필요하다는 단점이 존재
Dilated convolution
필터가 필터의 길이보다 큰 범위에 적용되어 특정한 step 으로 input value 를 skip 하는 것
연산량의 증폭 없이 크기 순서에 따라 receptive fields 를 늘려감
네트워크가 일반 convolution 보다 효과적으로 coarser scale 을 구성하도록 함
Pooling/strided convolution 과 유사하나 input 과 output 이 같은 사이즈임
stacked dilation convolutions 는 매우 큰 receptive fields 를 그저 몇 개의 layer 만으로도 가능하도록 함 (네트워크를 통해 input resolution 을 보존하면서 연산 효율성 또한 유지)
Dilated causal convolution
Long-range temporal dependency 를 위해서 dilated convolution 을 사용
이 논문에서는 dilation 이 각 레이어마다 limit 까지 double 로 진행
intuition :
1) dilation facotr 를 exponential 하게 증가하는 것은 depth 와 함께 receptive field 를 exponential 하게 키우는 결과를 냄
2) 이런 block 들을 쌓는 것 (stacking) 은 model capacity 와 receptive field size 를 더 커지게 함
Softmax distribution
개별 오디오 샘플에 대한 조건부 확률을 모델링하는 방법에는 mixture model 을 사용하나 (mixture density network, MCGSM(mixture of conditional gaussian scale mixtures))
데이터가 image pixel intensities 나 audio sample values 처럼 implicitly 하더라도 soft distribution 이 더 잘 동작 -> categorical distribution 은 shape 에 assumption 이 없기 때문에 flexible 하고 더 쉽게 임의의 분포를 모델링 가능
Raw audio 는 일반적으로 하나의 timestep 당 16-bit integer values 의 시퀀스르 저장, softmax layer 는 possible values 를 모델링하기 위해 timestep 당 65,536 개의 확률 결과가 필요.
이것을 더 tractrable 하게 만들기 위해 데이터에 mu-law companding transformation 을 적용, 256 개의 possible values 로 quantize (-1 < x_t < 1, mu=255)
이런 비선형 quantization 은 간단한 linear quantization scheme 보다 더 나은 reconstruction 생상
speech 에서는 이 quantization sounded 이후의 reconstructed signal 이 원본 음성과 더 유사하다는 것을 발견

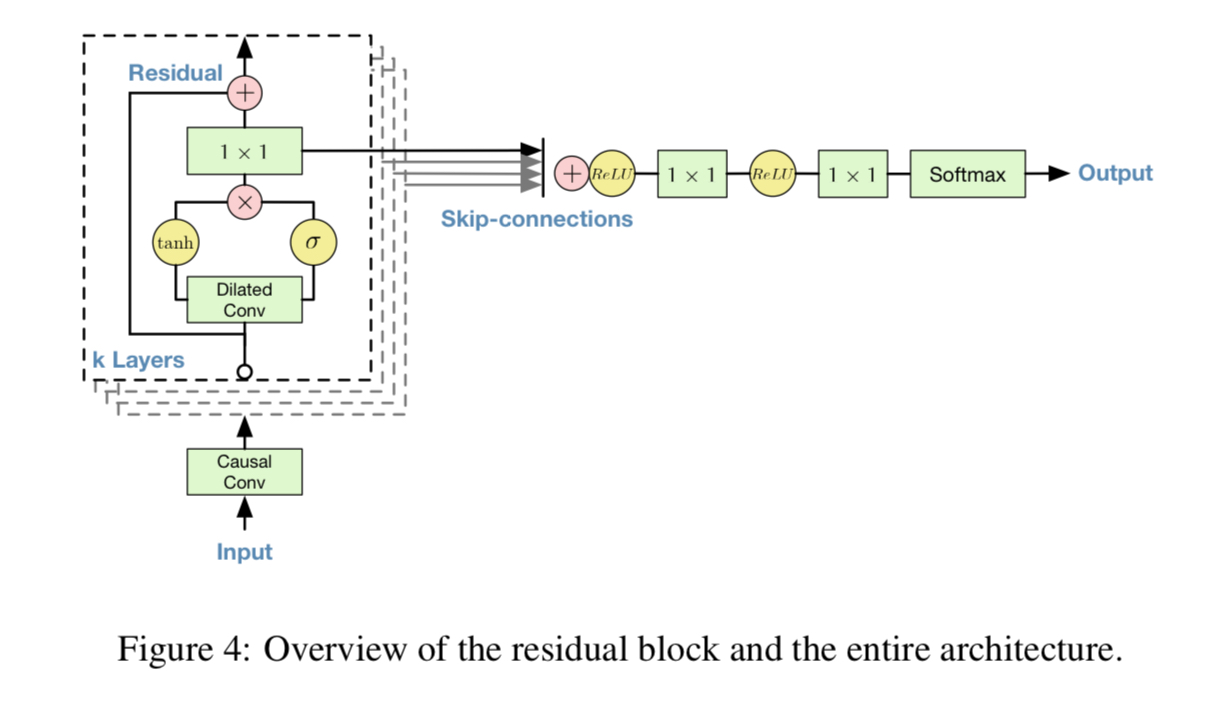
Gated Activation Units
Gated PixelCNN 에서 사용된 것과 동일
초기실험에서 audio signals 모델링을 위해서는 이런 비선형성이 ReLU 보다 더 나은 결과를 낸다는 것을 발견
특정 레이어에서 생성한 local feature 를 filter, 이 filter의 정보를 다음 레이어에 얼마나 전달해줄지를 gate 로 정함
Residual and skip connection
Convergence 를 더 빠르게 하고, 더 깊은 모델을 학습하기 위해 사용
Context stacks
보완적인 방법으로 seperate, smaller context stack 을 사용하여 오디오 신호의 긴 부분을 처리하고, 큰 wavenet 에 지역적으로 조건을 줘서 오디오 신호의 작은 부분만을 처리하도록 함
multiple context stacks 를 여러 길이와 hidden units 개수와 함꼐 사용 가능
큰 receptive fields 를 가진 stacks 는 레이어 당 더 작은 units 를 가지고 있음
context stacks 는 더 낮은 frequency 에서 동작하기 위한 pooling layer 를 갖고 있음, 이것은 연산요구량이 수용가능한 수준을 유지하게 하고 긴 timescales 에서도 temporal correlations 를 모델링할 때 적은 양이 필요하다는 직관도 유지함
Conditional wavenets
다른 input variables 로 wavenet 생성에 가이드를 해줄 수 있음
예를 들면 speaker identity 를 전달해서 speaker 선택 가능
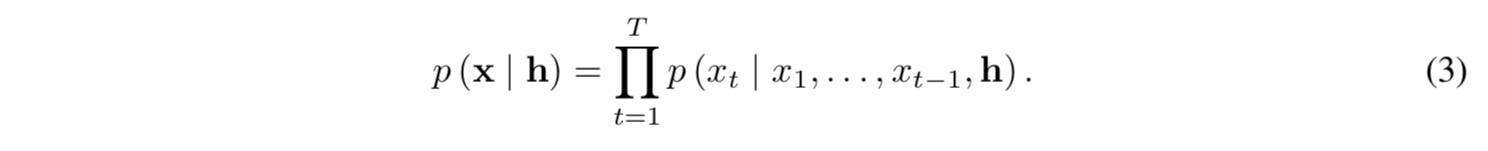
conditioning model 을 위한 두 가지 방법
1) global conditioning
하나의 latent representation h 를 전체 timestep 에 걸쳐 output 분포에 영향을 주는 것
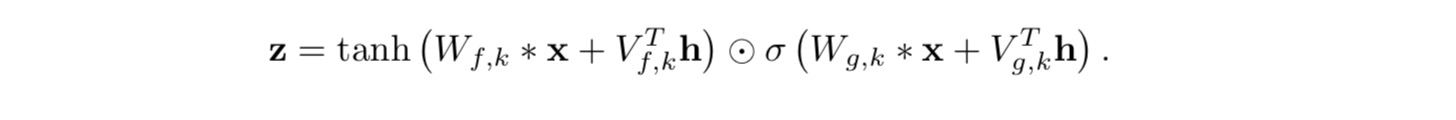
2) local conditioning
두번째 timeseries h_t 로 transposed conv 를 이용해 (audio signal 보다 sampling frequency 가 낮을 수 있기에) audio signals 로써 같은 resolution 에 새로운 time series y=f(h) 가 맵핑 되도록 함
V_{f,k}*y 는 1x1 conv, transposed conv 대체로 V_{f,k}*h 를 time 을 가로지르게 반복할 수 있지만 우리 실험에서 성능이 보다 조금 낮게 나옴
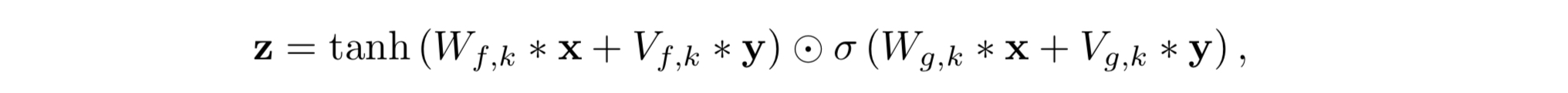
Experiments
Audio modeling performance 측정
1. multi-speaker speech generation
VCTK(44h, 109 speakers), conditioned wavenet(one-hot vector 형태로 speaker id 전달)
single speaker 보다 multi speaker 가 더 좋은 결과를 생성. 숨소리, 입 움직임 만큼 음향과 녹음 품질을 잘 따라함
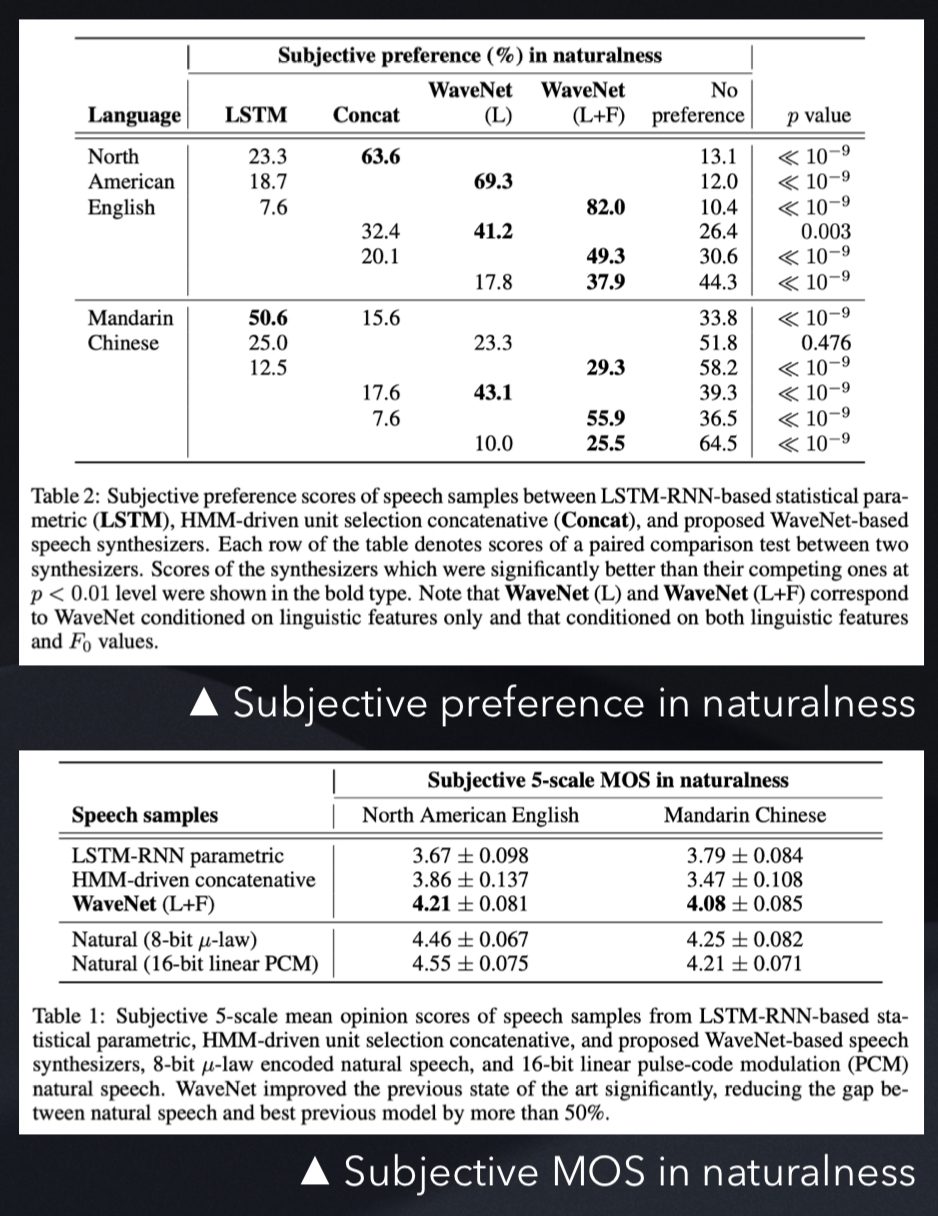
2. Text-to-Speech
north american english(24.6h), mandarin chinese(34.8h) 둘 다 여성 성우 녹음
L : conditioned on linguistic features
F : conditioned on logarithmic fundamental frequency (log F0) values
L 만 있는 WaveNet 의 경우 자연스럽지 않은 은율을 가지는 경우가 있는데, 이것은 F0 contours 의 long-term dependency 때문
두 가지 다 사용한 경우에는 더 낮은 frequency (200Hz) 에서 실행되기에 F0 contorous 에 존재하는 long-range dependences 학습 가능
3. Music
MagnaTagATune(200h), Youtube piano (60h)
receptive field 를 키우는 것이 중요
특정한 태그가 주어지는 음악 생성 기능, 각 학습 클립과 관련된 태그의 binary vector representation 에 의존하는 biases 를 추가하여 샘플링 시 여러 부분을 조절할 수 있도록 함
4. Speech recognition
Dilated convolutions 의 레이어들을 가진 waVenets 는 receptive field 를 LSTM 에 비해 효율적으로 길게 늘릴 수 있음
TIMIT dataset 사용
Dilated convolutions 뒤에 mean-pooling layer 를 추가해서 10ms 단위로 spanning 된 coarser frames 를 activations 에 누적
pooling layer 이후 몇 개의 non-causal convolutions 로 이루어져 있고, 두 개의 loss 사용 (하나는 다음 샘플을 예측, 다른 하나는 프레임을 분류)
하나의 loss 만 쓰는 것보다는 더 나은 결과가 나오며, 우리가 알기에 제일 좋은 스코어인 18.8 PER 달성
Conclusion
waveform level 에서 audio data 를 직접 구성하는 deep generative model
Autoregressive 하며, casual filters 와 dilated convolution 을 합쳐서 receptive fields 가 depth 와 함께 exponential 하게 커지도록 하였으며, 이것은 audio signals 에서 long-range temporal dependencies 를 모델링하는 데에 중요한 요소
다른 input 에 대해서도 condition 할 수 있음
global (e.g. speaker identity) / local (e.g, linguistic features) way
현재의 best TTS system 보다 주관적으로 자연스러운 샘플을 생성
Music audio modeling, speech recognition 에 적용했을 때 유망한(promising) 결과를 보여줌
References
FastSpeech2
https://arxiv.org/pdf/2006.04558.pdf
WT
https://tech.onepredict.ai/94d98ece-06be-4215-b5ef-87a58ab8d2e3
DTW
https://m.blog.naver.com/plasticcode/221430090062
Likelihood
https://data-scientist-brian-kim.tistory.com/91
https://xoft.tistory.com/30
WaveNet
https://arxiv.org/pdf/1609.03499.pdf
https://joungheekim.github.io/2020/09/17/paper-review/
https://music-audio-ai.tistory.com/2
'공부 > 논문' 카테고리의 다른 글
| VALL-E X (0) | 2025.03.23 |
|---|---|
| FastSpeech2 (0) | 2025.02.01 |
| HYPERTTS: Parameter Efficient Adaptation in Text to Speech using Hypernetworks (0) | 2024.12.10 |
| A Study on the Efficacy of model pre-training in Developing Neural Text-to-speech System (0) | 2024.12.09 |
| Adapting TTS models For New Speakers using Transfer Learning (0) | 2024.12.04 |